
Something I’ve learned from working on a startup is that there are too many options. There’s no management to tell you which way you should be going. You’re too early to completely follow your customer’s judgement. And everyone seems to want something.
Traditionally, I’ve always used a product prioritization matrix.

impact and effort matrix
However, being the sole-judge, it was easy to get too excited with what I wanted to build next and forget what customers actually wanted.
This made it super fuzzy to think about which items to go after next, and not enough conviction that it was always the right thing.
Prioritizing without decisions
If you think about it, everything on the prioritization matrix is just a x,y coordinate.
If we have the right formula to calculate cost and impact, we can plot all of our features.
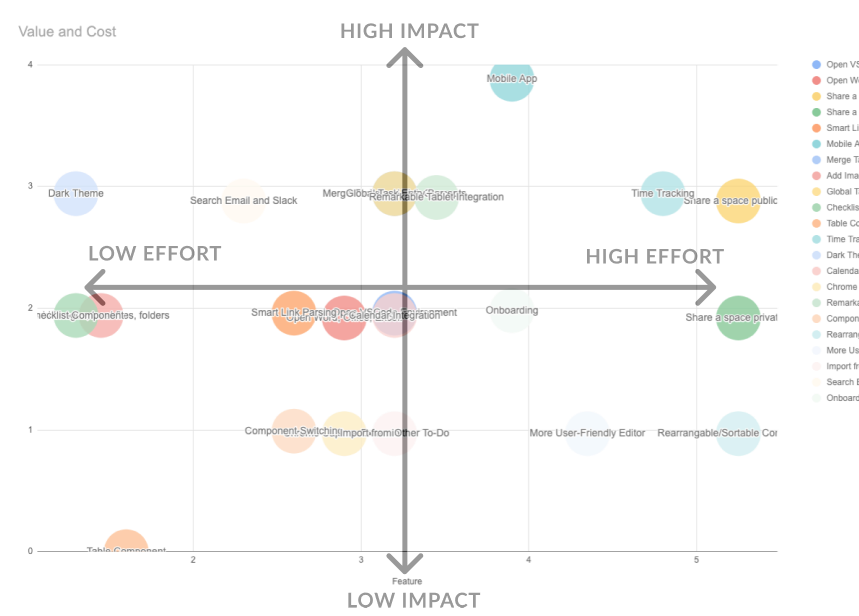
quantitatively graphing my features
For any bubble on the chart, we should be able to clearly calculate why it has a certain impact score, or a cost.
This puts everyone on the same page about the feature to build next.
How it works
We’ll come up with ways to score both impact and cost, and plot our points
Calculate Impact
The first step is picking the criteria that define impact for your team.
For example, here are a few questions that I use to judge our features:
- Expected - Do customers expect this feature from us? (e.g. competitors)
- Wow Factor - Does building this make our users go wow?
- Need by Others - Is this a dependency for other items?
The trick is to make the answers boil down to a number. In my case, a series of 1’s and 0’s that represent yes and no answers. (binary answers require the least thinking and debate)
| Feature | Expected | Wow | Need by Others | Impact |
|---|---|---|---|---|
| add checklist | 1 | 0 | 1 | 2 |
| share space | 0 | 0 | 1 | 1 |
| time tracking | 1 | 1 | 1 | 3 |
The SUM of all the columns is the final impact score. You can also add multipliers to assign different weights to skew one criteria over the other.
The more granular you make your criteria, the more varied your impact scores will be. You’ll also be to articulate to your team why one feature is more meaningful than another.
Adding Dev Effort
To complete your prioritization matrix, you need to add in an estimated cost for developer effort.
I use t-shirt sizing for my cost column. So I estimate effort on a scale of 1-3 depending on how big an item is.
| Feature | Impact | Estimated Cost |
|---|---|---|
| add checklist | 3 | 2 |
| share space | 1 | 1 |
| time tracking | 4 | 3 |
You can then plot the cost vs impact score as a scatter chart, and get a working plot.
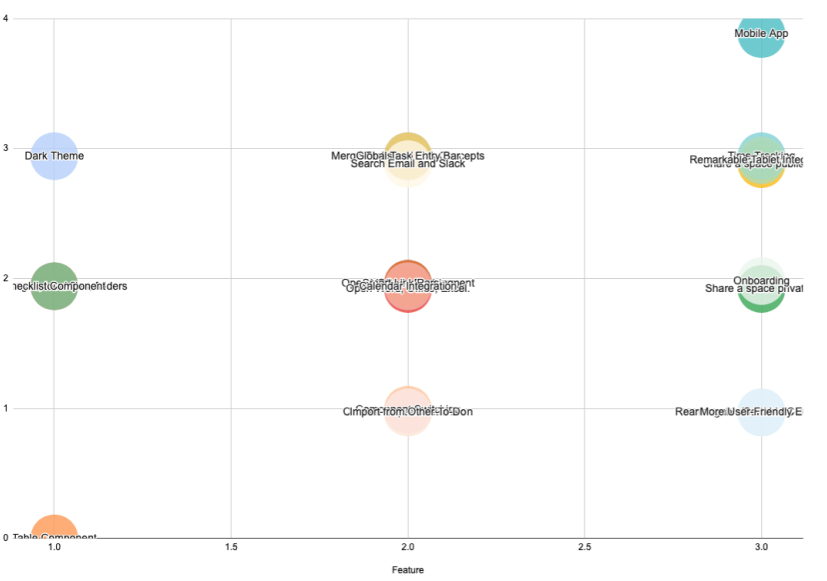
However, you’ll realize that the bubbles begin to overlay each other. This is because there is too much overlap in the costs among items.
To overcome this, I multiply the total cost with a randomize function.
=D2*(1+RANDBETWEEN(1,5)*0.15)
This adds variance. A good random factor helps us consider the completion of items ahead of schedule, and behind schedule.
I also apply a similar variance to the impact column to shuffle the items around a tad more.
Final Decisions
Here is my final plot:
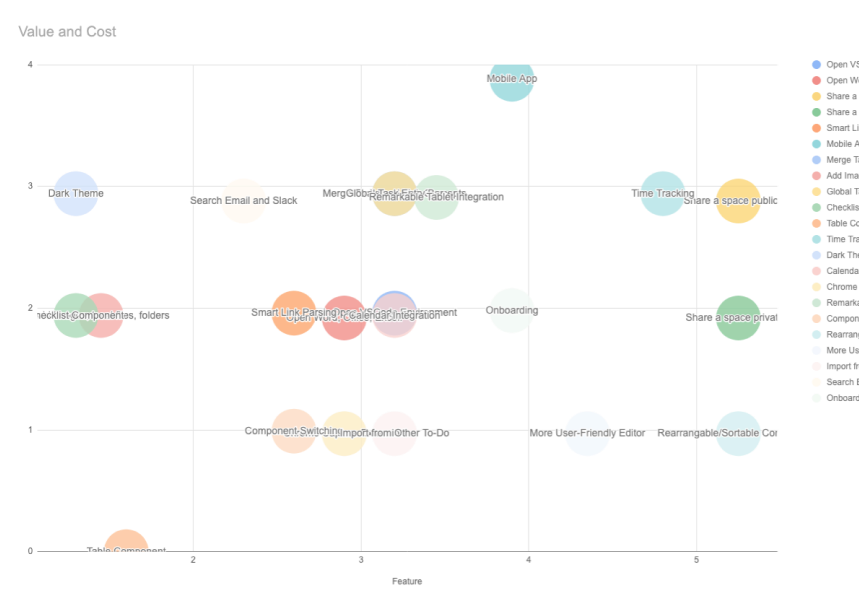
and the final feature table looks like
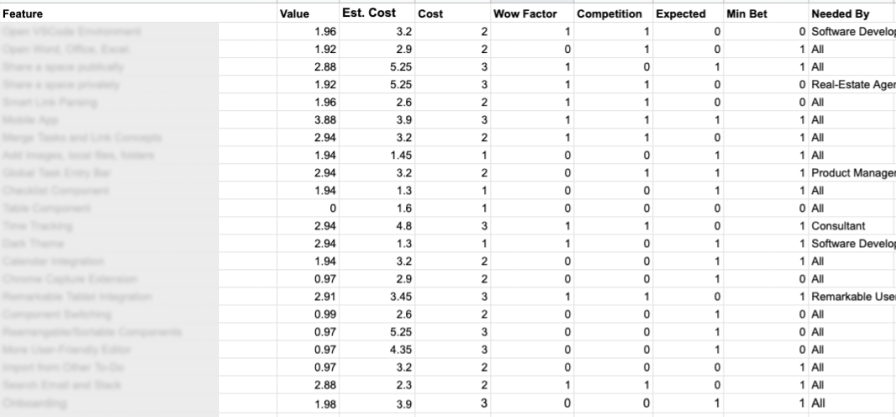
When deciding to pick the next items for the sprint, we rank by items that have the highest impact, and work backwards to what we can fit in.