
I read Hacker News religiously. It’s part of my everyday routine. I read articles when I wake up, as I eat lunch, and before I fall asleep.
HN allows you to upvote articles. Upvoted articles appear in a personal “upvoted submissions” section so that you can find them again later.
However, the problem with upvoting is that there is no good way to search through all the articles you’ve upvoted. By default, Hacker News comes with a search bar, but that searches all of the articles people have submitted over time and not necessarily the ones you upvoted.
Problem
I wish there was an easy way to search through all of my HN Articles that I have previously upvoted. I only want to search my personal knowledge base.
I started this project because I was looking for an article that interviewed Foursquare founder Naveen on how he organizes his work. This was important because I wanted to reach out to Naveen about something I was working on - and this was my way to recall his workflows. Other than his name, I didn’t remember many specifics from the article.
Doing a regular search on HN for the “Naveen” or “Naveen Interview” surfaced way too many results. I didn’t really know the title - just roughly what the content was about.
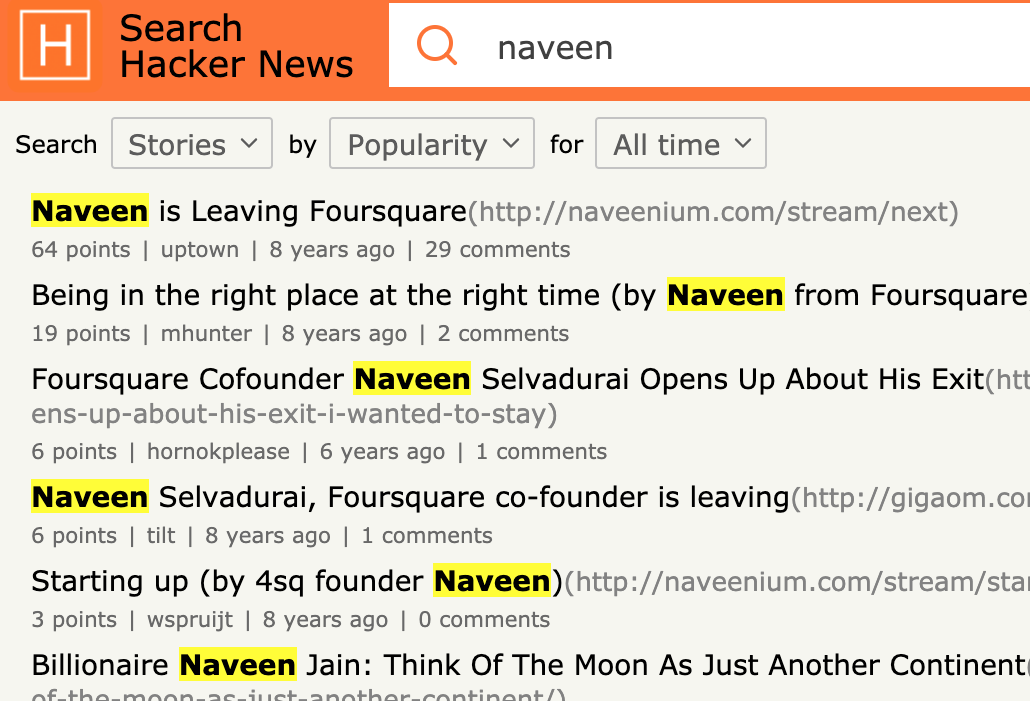
What I really wanted was to search through the content of my upvoted articles. That way I could get more than actual titles.
Fortunately, there was a way I could do this without indexing the world - Google Custom Search Engine.
The Plan of Action
There were three questions I had to answer:
- Will Google Custom Search Engine work for any set of links?
- How can I export my upvoted submissions from HN?
- Would CSE search only the subset of articles I gave or mix-in other garbage as well?
The last one was a hope. I would think it would hold true, but I wouldn’t have been surprised if it wasn’t the case.
Setting up CSE
Setting up a Custom Search Engine was super easy with Google. It’s as easy as clicking on “New Search Engine” and adding links of websites.
On intial setup there was no way to bulk add a lot of websites. However, after creating a search engine, and then editing it revealed that there is an “advanced” option. You could then paste in a bulk list of links.
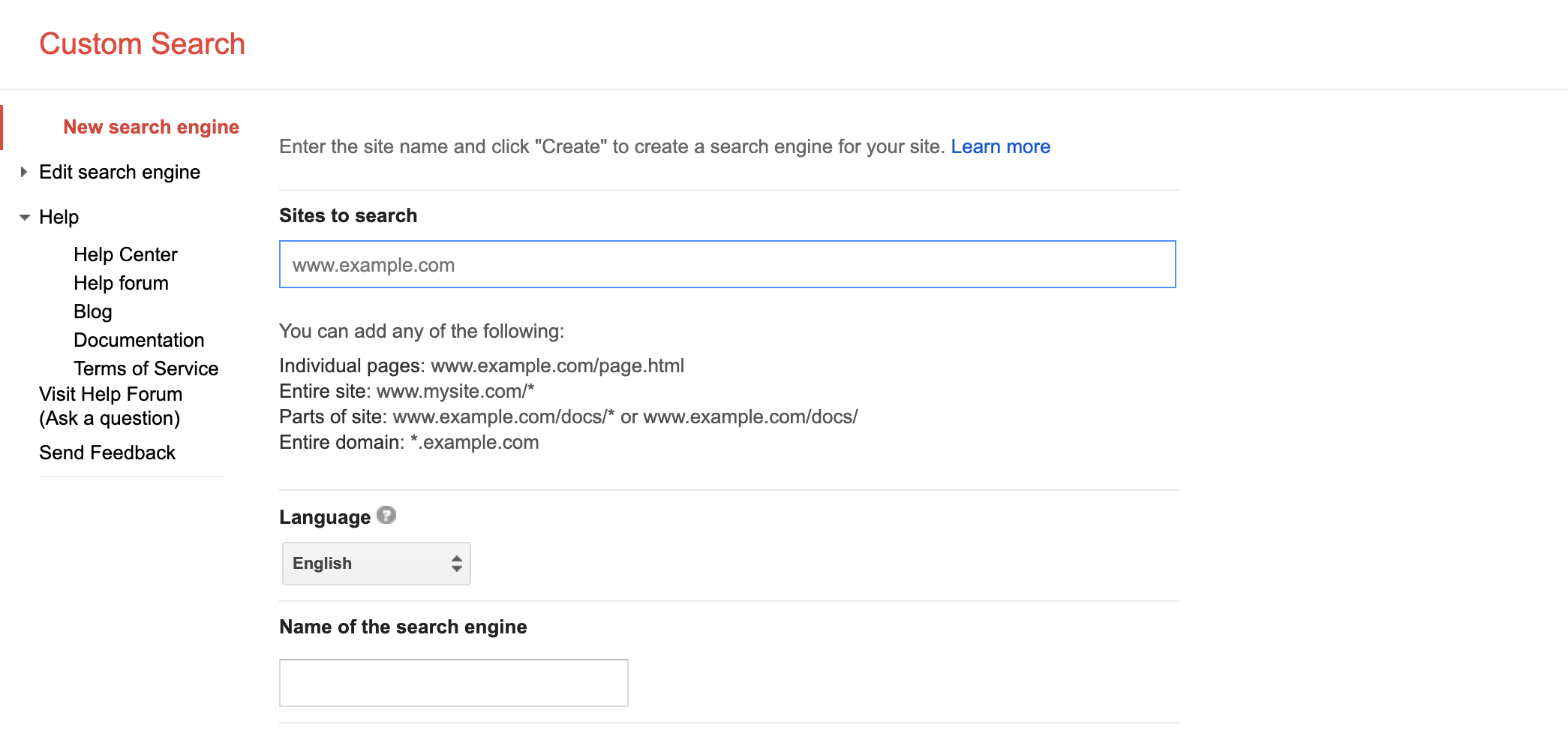
I did not find an API that let me add links programatically. That means I’d have to do an occasional upload of new links - which is ok.
Exporting Upvoted HN Articles
I thought getting the upvoted articles out of HN would be straightforward - but this was the hardest part. I knew the HN exposed an API for years, but after some digging it was clear that there was no way to get the upvoted articles.
I dropped them an email to verify. Alas, the worst was true. There was no easy endpoint to get all of my articles:

This was most dissapointing. But I figured there had to be a way. I mean there were so many HN clones on the web - it seemed like someone must have had to have implemented this. Even Octal, my favorite HN client, lacked a way to show upvoted submissions.

The only thing option that was left was to scrape my upvoted submissions. That was my last resort option.
I continued to scour Github for HN clones and see if I could reuse anything, I stumbled upon a repo that recommended stories based on articles that you had previously upvoted. My eyes widened a bit. It was called HN Story Recommendations. Reading the readme revealed it leveraged a scraper that converted upvoted articles to JSON. Perfect.
Fortunately, HN hadn’t changed much in four years - so the code still worked
The script only gave back the ids of the upvoted articles. So I forked the code and wrote a quick script to convert the Ids to links. The script formatted the links so I could just paste into the Custom Search Engine.
Comparing Results
I uploaded the links to CSE and the moment of truth came when I searched for “Naveen” again. The results were instantenous and CSE only searched the articles I gave it. I was happy that it found the article I was looking for!
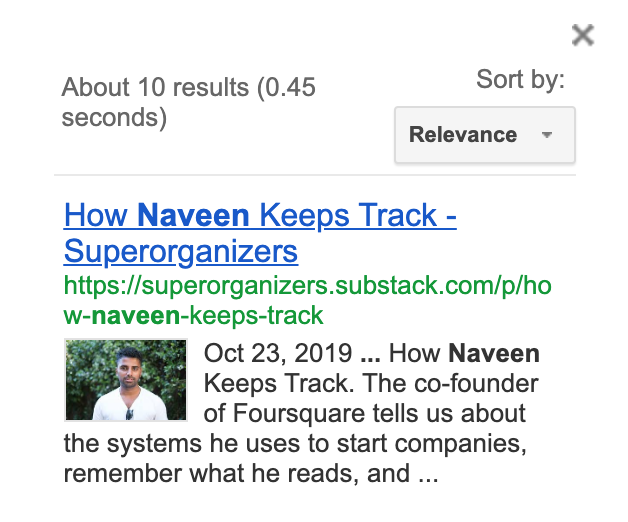
Unfortunately, the website has a paywall for that article now.
Albeit, I was still happy that the custom search engine worked. Even though the article was locked, the SuperOrganizers website still contained a lot of good information.
Personal Knowledge Base
Hopefully, this method works for you. If you have a better approach - leave it in the comments below.
I’d love to learn more about your personal workflows with curating information and how you manage your personal knowledge base? Please reach out to me or leave a comment below - I would love to chat.
I’m currently working on a tool to create a better way to manage all of our information. It is called Amna. Amna is designed to help with context switching and information retrieval. It’s still super early. Looking for feedback and thoughts.